Abstract: Machine and language models of computation differ so greatly in the computational complexity properties of their representation that they form two distinct classes that cannot be directly compared in a meaningful way. While machine models are self-contained, the properties of the language models indicate that they require a computationally powerful collaborator, and are better called models of programming.
On Two Views of Computation in Computer Science
Many terms in computer science are overloaded, but none are more surprising than the term “computation” itself. I became aware of this when, while preparing for my Curry On talk about computational complexity aspects of software correctness, I read an interesting debate about a 2012 blog post by Scott Aaronson, The Toaster-Enhanced Turing Machine, and further echoes of it in other published writings that will be mentioned below. The issue is two fundamentally different notions of “a model of computation” as seen by computer-science theoreticians originating in two different branches of theoretical computer science, sometimes called Theory A and Theory B (also here), although I prefer the categorization by Oded Goldreich, who calls them Theory of Computation (TOC) and Theory of Programming (TOP) respectively, and argues that the two are essential yet rightfully separate sub-disciplines of theoretical computer science. In the context of this discussion, the two can be narrowed more precisely to the fields of computational complexity theory and programming language theory. My goal in this post is to show that while both sides use the term “model of computation” (or even just “computation”), they each refer to something radically different. I intend to show that the difference is not a matter of aesthetics, but can be objectively and mathematically defined.
I must take great care in writing this because, unfortunately, I lack the knowledge to make any definitive claims on the subject. However, I have been unable to find any good discussion of this topic online, and the very existence of the notes discussed below suggests that one does not exist. My contribution, therefore, is merely an attempt to start a conversation which would hopefully draw those who are more qualified to contribute actual substance. I hope that whatever errors I make are superficial and could be forgiven (though I would appreciate readers pointing them out).
I find this subject important for two reasons: 1. I hope it would help to uncover this overloading and thus clarify debates and make them more fruitful, and 2. because I think this divide touches on the core concept of computer science, and helps delineate the two theoretical disciplines as each focusing on the very heart of computer science but from a very different point of view. I should disclose that, while by no means a researcher, my personal interests draw me more to the TOC/Theory A/complexity theory view, and believe it is the TOP side that sometimes overreaches. I hope my personal aesthetic preferences do not skew my discussion too much.
Computation Models vs. Programming Models
The schism goes back to two of the earliest models of computation: Alonzo Church’s lambda calculus and Alan Turing’s automatic machine, first named “Turing machine” by none other than Church. More precisely, the schism originates in a modern categorization of those two models, although I believe there is some merit in projecting those interpretations back to Church and Turing themselves, who differed greatly in their personal interests. The two categories are language-based models of computation (of which Church’s lambda calculus is an example) and the machine-based models of computation (Turing machines are an example).
The particular debate on Aaronson’s blog is over the Church-Turing thesis. There are debates over modern interpretations and extensions of the thesis in the context of physical systems, quantum computation, and the possibility of hypercomputation, but this particular debate is about nothing of the sort, and purportedly applies to real-world software. The post and the entire discussion in the comments are interesting (I particularly enjoyed this comment by Paul Beame and this one by Itai Bar-Natan), but here I will present a small selection.
Neel Krishnaswami, who represents the TOP view, argues the following
It’s really weird that the Church-Turing thesis, which is ridiculously robust at first order, falls apart so comprehensively at higher type.
and continues:
[T]he claim that all Turing-complete languages are equivalent in expressive power is false. It is only true when inputs and outputs are numbers (or other simple inductive type). I don’t mean false in some esoteric philosophical sense, either: I mean there are counterexamples… Note that higher-type inputs and outputs have a lot of practical applications, too… So the fact that the higher-type generalization of the Church-Turing thesis fails is of immense interest, both theoretically and practically.
Aaronson, who represents the TOC view, replies:
I disagree with the idea that we can or should worry about “higher types” when formulating what the Church-Turing Thesis is supposed to mean. From the perspective of the end user, a computer program is something that takes various strings of information as input and produces other strings as output.… I’d say that, when formulating a principle as basic and enduring as the Church-Turing Thesis, we have no right to weigh it down with concepts that only make sense “internally,” within certain kinds of programming languages. … I don’t mind if someone formulates a “Higher-Type Church-Turing Thesis” and then knocks it down. But they should make it clear that their new, false thesis has nothing to do with what Turing was writing about in 1936, or with… the clearest way to understand the Church-Turing Thesis today: as a falsifiable claim about what kinds of computers can and can’t be built in physical reality.
Krishnaswami retorts:
[T]he concept of type is not tied to a programming language, or indeed even to computation — they were invented before computers were! … Types serve to structure the purely mathematical concept of equality, which is the concept upon which your formalization of expressive power relies.
To which Aaronson answers:
Your viewpoint — that the logicians’ abstract concept of a “type” comes prior to talking about computation — is one that’s extremely alien to my way of thinking. (If it were so, how could I have spent a whole career worrying about computation without ever needing ‘higher types’…?) For me, the notion of computation comes before types, before categories, before groups, rings, and fields, even before set theory. Computation is down at the rock bottom, along with bits and integers. Everything else, including types, comes later and is built on top.
We can summarize the two positions in the following way: The TOP people say, “computations are programs, and programs are mathematical objects whose structure is captured by their types; the two models of computations are equivalent when asked to represent first-order functions, but diverge when asked to represent higher-order functions”. The TOC response is, put simply, “what the hell is a function?” Just as a falling apple doesn’t compute integrals — it just falls — so too Turing machines and any other machine model compute neither higher-order nor first-order functions; they compute bits. What imaginary mathematical concepts we then choose to describe those computations is a different matter altogether, one that does not affect the nature of the computation just as calculus has had no impact on the behavior of falling apples.
To Aaronson, functions are an “imagined” concept, a human interpretation applied to a computational process (among other things). Computation itself is a physical process — albeit abstract, in the sense that it may have multiple physical implementations — whose idealized model may serve as the foundation for higher concepts1. For Krishnaswami, functions and types are fundamental, primitive constructs, that are precursors to computation (which, I presume, is perceived to be a purely mathematical concept to begin with). To use more established nomenclature, TOP people are familiar with the distinction between syntax and semantics, but is a computation equivalent to its mathematical semantics, or is it a system, yet another level of description, distinct from semantics?
This can be said to be nothing more than a different choice of foundation, where in each one the other can be encoded as a high-level abstraction. In mathematics, sometimes solving a problem requires finding the right orthonormal basis to describe its domain. Are machine models and language models two such “orthonormal bases” to describe computation — different but equal representations — or are they qualitatively and fundamentally different? Can we prove that the TOP view requires an additional “imaginative” step? Can we prove that semantics is distinct from the actual system?
To physicists, the answer to the question is an obvious yes. If the string 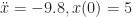
In a blog post, Andrej Bauer discusses the importance of representation. He gives two examples. In the first, he considers the following representation of Turing machines: we represent a TM as simply 1 if it terminates on the empty tape, and as 0 if it doesn’t. In this representation, he points out, the halting problem does not exist! A reasonable representation, he says, is one that lets us perform the relevant operations for the represented object; in the case of a Turing machine, we would like to simulate the machine, and the aforementioned representation does not let us do that. He then gives another example. For any computable or non-computable function 
1 or 0 dependent on whether the machine halts or not on the empty tape, the halting problem also disappears. How can we identify such a representation that actually “does all the work”? Easy — we investigate the computability of the language of legal representations. The language of representations of TMs that I presented is itself undecidable. In the comment by Bauer below, he gives a different justification for why this representation is not, in fact, reasonable, but our justification naturally generalizes to complexity, too. We may ask (and easily answer) how much work is done by the representation by investigating the complexity class of the language. So in addition to the question of utility, we can classify representations along the axis of their language complexity.
We now turn this line of reasoning on representations of computation itself by asking what is the computational complexity of deciding whether a given string of bits encodes a valid (well-formed) computation in a given model? Consider some machine models: the Turing machine, random-access machine, cellular automata, boolean circuits, boolean networks, neural networks, P systems. Now consider some language models: Church’s untyped λ-calculus, π-calculus, System F, System Fω, System λΠ. All those representations pass Bauer’s first condition — they are directly useful for simulating computations — but they differ widely with respect to the second test, namely the complexity of deciding the language of the representation.
For the Turing machine, if we choose to interpret a jump to a nonexistent configuration as a “halt” instruction (a rather natural interpretation), then the required complexity is zero (by that I mean that there exists a natural representation that requires no translation and no validation, i.e., every string specifies a valid machine, and every machine can be specified in that encoding). Zero is also the complexity required to validate appropriate encodings of any of the other machine models (well, maybe not P systems, but certainly lower-level biological computation models). As for Church’s untyped lambda calculus, I believe that the best we can do — if we allow variable shadowing, which complicates interpretation — is validation in linear time and logarithmic space by a PDA (the main issue is that parentheses are meaningful). But for the other language models (the typed ones; I haven’t thought about π-calculus enough), very considerable complexity and a Turing-complete system are required only to validate if a computation is well-formed (for λΠ, that validation is no longer computably tied to the length of the input; it can be larger than the complexity of the computation itself). This clearly shows that the computational model isn’t self-contained, but essentially requires a computationally powerful external collaborator: a programmer and/or a compiler. If a model requires such external work, it is not a model of computation but of programming.
Where precisely we choose to draw the line between a programming model and a computation model may be up for some debate. Church’s untyped calculus seems to be a borderline case. But it is worth mentioning that the notion of a function doesn’t even appear in Church’s 1936 description of lambda calculus, let alone a higher-order function (while the word “variable” does appear, it is clear from context that it is only meant to intuitively communicate the operations of the rewriting rules). Computation by untyped lambda calculus in Church’s paper is reasonably described as a relatively simple rewriting system, which is a special case of a nondeterministic abstract state machine, but, of course, none of those terms existed in 1936. However, when PL theorists say “lambda calculus” today, they seem to mean something different, and use it as shorthand for lambda calculus plus functional denotational semantics.
In any event, the vast complexity difference leaves no question whatsoever that, say, a Turing machine is essentially different from some typed lambda-calculus system. Like entropy, computational complexity is absolute and not subject to a point of view. It is not for me to say which words scholars should use, but when PL researchers say “computation model” when referring to one of the language systems, they mean something qualitatively different from what TOC people mean. System Fω is not a model of computation in the same sense that the Turing machine or digital circuits are.
In fact, given a rich enough type system, we could burden an arbitrary portion of the computation on the type inferencer or on the collaborator (programmer) and the type checker. We could write programs whose types decide computationally difficult question, ostensibly making the actual program answer them in zero time. Obviously, computational complexity theory does not “fall apart” when we use a rich formalism.
Krishnaswami admits there is a difference between computation and its formal representation:
You’re free to think about computation as acting on bits… but for those bits to do us any good, they have to actually represent something (e.g., data structures).
To represent anything, a system needs an observer that assigns its behavior meaning. But the observer required here isn’t the user of the computation, who, after all only cares that the screen’s pixels are lit up in an interesting way or that the airplane’s control surfaces are sent the right signals — i.e., about the bits — but the human programmer.
Viewing machine models and language models as competing is a mistake that confuses computation (the system) with programming (concerned with syntax and semantics), two fundamentally different activities. This confusing presentation of machine and language models as standing in opposition to one another cannot be expressed more starkly than in this somewhat trollish post by Bob Harper.
I don’t wish to address every point Harper makes, but just to focus on this one:
The machine models have no practical uses at all… [They’re] worthless from a practical viewpoint.
I find it curious that Harper thinks that machine models are worthless while using a physical implementation of one to form that very thought and another to type it into. He probably means that he believes they are worthless as programming models, but that is not what they are. To be even more precise, machine models are far from ideal programming models when the programmer is a human. But some machine models — in particular digital circuits (that are often used to model natural, cellular computation) and neural networks — are great “programming” models for a programmer of a different kind, one that is generally incapable of performing complex computation itself.
It is true that a machine models could be “lifted” to serve as a programming model, and it is in that sense that Krishnaswami and Harper compare the two. Indeed, Krishnaswami’s “counterexamples” make sense only if you treat the Turing machine as a programming model (with canonical representations of types), and even then only if you consider “computing a function” not as mapping a set of inputs to a set of outputs, but as the requirement to express an inhabitant of a certain function type (in the type theory sense). That difference between considering a function as a mapping between two sets and as an inhabitant of a function type is not just a matter of perspective: it is a matter of more computational work. It is a different, harder problem. In the type theory interpretation, the computation needs to compute the target element and check a proof that the element is in a certain set. Really, those are two problems, not one, and you certainly can’t fault a model for not solving a problem you didn’t ask it to solve. A machine could solve that problem (simulate type checking) if you asked it to. That a language model solves that problem “automatically” doesn’t matter if the same price (computational complexity) is paid by a collaborator. Otherwise, I could create a language model that solves all NP problems in constant time by defining my language’s type-checker to require and verify a proof certificate with every input problem, and my model would then reduce the input to “yes” in one step. No one would believe my language actually solves a hard computational problem: it simply pushes the difficulty to the collaborator. In fact, some type systems are Turing complete, so those language “computation models” could decide any decidable question in zero time. But, of course, that’s just ignoring the hidden computation that takes place in those models, and is carried out by the programmer and/or interpreter.
In any event, this type-theoretic view, has little to do with the TOC view of computation or with the machine models’ “intended” use. In a report written in 1996, Theory of Computing: A Scientific Perspective, Oded Goldreich and Avi Wigderson, write that:
TOC is the science of computation. It seeks to understand computational phenomena, be it natural, man made or imaginative. TOC is an independent scientific discipline of fundamental importance. Its intrinsic goals… transcend the immediate applicability to engineering and technology.
We only need to look at the modern work on circuit complexity, the great interest in quantum computing or the celebrated work of Leslie Valiant, who studies complexity theoretical aspects of learning and evolution, to see that questions of programs written by a human programmer are far from the only concern of complexity research. It is natural, therefore, that the self-contained machine-based computational models would be more appropriate for such a discipline.
Harper’s attack on the utility of machine models and lack of modularity is tantamount to an architect saying to a chemist, “both of our disciplines concern the arrangement of molecules, yet my discipline is superior, as yours doesn’t even have the modular notion of a room!”
To the architect, the concept of a room is real. Indeed, it is the the material constructing it that is a detail that can change in ways that may not be essential. The walls can be made of wood, mud, concrete, glass, or even intangibly rendered by a graphics card. To the chemist, however, a room is an abstract, imaginary concept constructed by humans to describe certain large-scale configurations of molecules that are meaningful to them, and while chemistry may study steel or concrete, it may also study crystals, polymers or living cells. Debating which of those views is more correct or more useful than the other is silly.
It is telling that Turing’s interest lay elsewhere from Church’s. When discussing what Church and Turing themselves thought of the Church-Turing thesis, Andrew Hodges, Turing’s biographer, writes that Turing
was in many ways an outsider to the rather isolated logicians’ world, having a broad grounding in applied mathematics and an interest in actual engineering.
While Church was a logician through and through, Turing was interested in mathematical biology, digital circuit design and theoretical physics (he even considered the ramifications of quantum mechanics on physical computation), and was a pioneer of neural networks and genetic algorithms, in addition to his work on numerical algorithms (although in 1949 he described a program proof technique quite similar to Floyd and Hoare’s work, over two decades later).
Mathematics of Computation and Mathematics of Programming
Now that we have hopefully established the objective difference between computation and programming models and their different uses, we can read Harper’s claims more charitably as saying that machine models when used as languages are a bad fit for two uses that he has in mind: programming — i.e., the implementation of algorithms in real software — and algorithm specification and analysis (of human-made algorithms intended for implementation in software).
Whether or not the typed functional programming languages based on lambda calculus and advocated by Harper are indeed superior programming languages for real-world large scale software development is, unfortunately, an unanswered empirical question and far beyond the scope of this post. But as for algorithm specification, Harper knows that no one actually specifies algorithms directly in a TM or RAM language,
Rather, they write what is charmingly called pidgin Algol, or pidgin C, or similar imperative programming notation. That is, they use a programming language, not a machine! As well they should. But then why the emphasis on machine models? And what does that pidgin they’re writing mean?
He suggests:
There is an alternative… without… reference to an underlying machine… [W]e adopt a linguistic model of computation, rather than a machine model, and life gets better! There is a wider range of options for expressing algorithms, and we simplify the story of how algorithms are to be analyzed.
He then presents a cost-model for functional programming, the lack of which, he believes, has been the only substantial barrier to adoption by algorithm researchers. I am not at all qualified to judge the advantages and disadvantages of Harper’s proposed languages for the purpose of analyzing algorithms; they do offer rich, albeit arcane, modern-logic mathematical properties (but I don’t understand how parallel and sequential algorithms can be compared to one another in a unified notation in that framework, how concurrent algorithms are to be specified and analyzed without introducing complex concepts, and how quantum algorithms can be specified and compared with their classical counterparts; I am also not convinced that such arcane math is required for such a task).
Harper’s criticism suffers from two errors of very different kinds. The first is a categorical error, one of confusing a foundational principle with pragmatic ergonomics. The same accusation Harper levels at machine-based theories could be directed toward Harper’s own favorite formalism, which he elucidates in The Holy Trinity (by the way, it is clear that by “computation” he means “programming”):
If you arrive at an insight that has importance for logic, languages, and categories, then you may feel sure that you have elucidated an essential concept of computation—you have made an enduring scientific discovery.
In practice, those who use Harper’s “computational trinitarianism” of logic, types and cateogry theory to reason about programs, also do not usually use that beautiful correspondence between programs and proofs directly, opting instead for procedural proof “tactics”, which are more convenient in practice. This, however, should be used to undermine the fundamental importance of the theory, just as the convenient use of “pidgin Algol” does not discredit the foundational utility of machine model.
The other mistake is that the flaws Harper attributes to machine models are not flaws in the conceptual foundation of machine models at all, but with the choice of particular, “low level”, machine models (that are nonetheless of great fundamental importance due to the reasons I covered above) and their treatment as low-level programming languages, or “compilation targets”. Hidden in this critique is the assumption that a mental compilation of into those low-level languages is what underlies academic pseudocode. But the concept of machines does not require this compilation, and it is not true that the machines implied by this pseudocode are such low-level ones like TM or RAM.
Indeed, in Leslie Lamport’s formal specification and verification language, TLA+, algorithms may optionally be written in a pseudocode-like language, precisely of the kind Harper rejects, and yet they are compiled — for the purpose of formal reasoning — into a mathematical formalism for describing abstract state machines, yet those machines are at least as high-level and at least as composable as Harper’s languages.
Lamport justifies his choice of mathematical formalism with words that read like a precise mirror-image of Harper’s:
For quite a while, I’ve been disturbed by the emphasis on language in computer science… Thinking is not the ability to manipulate language; it’s the ability to manipulate concepts. Computer science should be about concepts, not languages. … State machines… provide a uniform way to describe computation with simple mathematics. The obsession with language is a strong obstacle to any attempt at unifying different parts of computer science.
In a short, more trollish version of the same article, he writes:
Computer scientists collectively suffer from what I call the Whorfian syndrome — the confusion of language with reality…Many of these formalisms are said to be mathematical, having words like algebra and calculus in their names. … Despite what those who suffer from the Whorfian syndrome may believe, calling something mathematical does not confer upon it the power and simplicity of ordinary mathematics.
Like Harper, Lamport bemoans the lack of properly defined semantics and a unified mathematical framework of academic pseudocode, but instead of a language model he offers a unified mathematical framework with clear and simple semantics, based not on treating each machine model independently as a low-level language, but on abstracting the general idea of a state machine to describe any computation model in a high-level, modular, mathematical way. This is no longer a self-contained machine model of computation but a true formalism (language), just not one based on lambda calculus or other linguistic models (like process calculi) but one designed to formalize all kinds of computations as (very) high-level machines.
Lamport’s mathematical model, TLA, based on abstract nondeterministic state machines and relatively simple logic, that is modular, allows for direct comparison of parallel and sequential versions of an algorithm, works equally well for sequential and concurrent algorithms, and can directly and naturally describe large-scale real-world software, neural computation, genetic algorithms and quantum computation (I’m not certain about the last one). TLA surpasses even the “linguistic” dependent types in unifying the description of an algorithm with the description of its properties — properties and algorithms not only use the same syntactic terms but are actually the same (model) objects — yet it only requires mostly familiar math (what he calls “ordinary math; not some weird computer scientists’ math”).
Algorithm specification and analysis is absolutely crucial for humans who create computations. But while it may be the case that algorithm analysis can learn thing or two about mathematical modeling of algorithms from language models, abstract state machines seem a great fit for this task as well. In the end, however, there can be many foundational theories as well as many formalisms for programming and reasoning about programs. Arguing about their aesthetic qualities — while intellectually interesting — is not what matters. What matters is how they perform when put to various practical uses.
- One can indeed imagine a foundation of math built on top of a machine model, say the Turing machine. The natural numbers could be defined as certain strings encoded on the machine’s tape, or even as the universal encoding of a machine that writes a number in unary on the tape and halts. A function could be defined as the encoding of a machine mapping input to output; a set could be defined by its characteristic function (BTW, such a foundation would be protected from paradoxes by undecidability; the physical realizability of computation serves as a natural protection from paradox). ↩

Leslie Lamport: (sent by email with permission to post)
I believe that computer science, like other sciences and like math once was, should be about the real world. What distinguishes it from other sciences is that other sciences treat continuous phenomena, while computer science is about phenomena that can be described as a collection of distinct events. More precisely, it’s about systems (such as programs being executed on a computer) whose behavior can be described as a partially ordered set of events. Such a system can be described by a set of behaviors—the set of all possible behaviors of the system. [N.B. I am using the term “set” loosely. In what I find to be the simplest mathematical formalism of all this, there are “too many” possible behaviors to constitute a set—in some versions of set theory, they form what is called a class.] For describing classical notions of correctness (e.g., Floyd-Hoare), no structure is required. Classical correctness means that each individual behavior satisfies some property. For other notions of correctness (e.g. correct performance) that involve average properties or probabilities of incorrect behavior, one also needs a probability measure on the set of possible behaviors. I have no practical experience with these other notions of correctness, so I will talk only about classical correctness.
A partial ordering of events is equivalent to the set of all total orderings consistent with that partial ordering. I have found that for the classical correctness properties of interest to industry and to programmers, a partial ordering of events is correct iff each of the total orderings consistent with it are correct. Therefore, we can simplify things by considering a behavior to be a total ordering of events and a system to be described by a set of all such behaviors. A classical correctness property is a set of behaviors–those behaviors that are considered correct. Since a system is also described by a set of behaviors, there is no meaningful distinction between a system and a correctness property.
A mathematical theorem asserts that every set of behaviors is the intersection of a safety property and a liveness property, where intuitively a safety property describes the finite prefixes of a behavior and a liveness property describes its infinite suffixes. (Infinite behaviors are useful abstractions of systems like operating systems that aren’t supposed to stop—just as planets orbiting a star forever is a useful abstraction in astronomy even for a temporally finite universe.)
I’ve found it most useful to describe a behavior as a sequence of states (the events being the state changes). (Others like to specify a behavior as a sequence of events/actions or as labeled state transitions; it’s easy to translate from one of these representations to another.) A safety property is most conveniently described by a set of initial states and a next-state relation that describes all possible state changes. In fact, every practical method of specifying behaviors I know of describes their safety properties essentially in this way. Most programming languages seem to specify only the safety properties of the programs written in the language; they don’t completely specify the behavior of programs that don’t terminate. Operational program semantics (which I believe are the only practical ones for non-trivial languages) effectively translate the program into an initial state + next-state relation representation. Since programming language people tend to suffer from the Whorfian syndrome (the confusion of language and reality), I wouldn’t be surprised if they don’t see that something like an SOS semantics is doing just that.
Programming language people devise various ways to describe the state of a program and its next-state relation. The Whorfian syndrome probably makes it impossible for many of them to realize that that’s what they’re doing. Their languages are quite complicated. (I measure the complexity of a language by how simple its semantics is, when represented formally in ordinary mathematics—which ultimately means 1st-order logic + ZF or some other simple set theory.) There’s good reason for such complexity. However, I learned long ago that if you’re not writing a program—that is something that real people are going to use to get real work done—then there’s no need to use something as complicated as a programming language. The TLA+ language uses ordinary math to specify the initial states and next-state relation, plus temporal logic to specify liveness. (Unfortunately, I haven’t found any better way to specify liveness.) This has the effect of making it easy to specify systems that can do things Turing machines can’t. But that seems an unavoidable consequence of simplicity. What kind of simple method of writing specifications would allow one to specify that a program should decide if a finite-state machine will halt but not to specify one that decides if a Turing machine will halt?
LikeLike
“For the Turing machine, if we choose to interpret a jump to a nonexistent configuration as a “halt” instruction (a rather natural interpretation), then the required complexity is zero.”
Can you expand on this a bit more? I can’t imagine any string of bits that you can validate as having any desired property without reading a single bit. It’s not even plausible to me that you can decide validity of a computation without reading all the bits (unless you relax “decide” and use things like the PCP, no small feat by any means).
LikeLike
Certainly.
First, assume that the simulated machine’s alphabet is {0, 1}. Now, suppose I could limit the largest machine I can take, here’s the encoding: the first bit is where to move if the current cell holds a
0, where “0” means left and “1” means right. The second bit is what to write if the current cell holds a0. The third bit is where to move in case of1, the fourth bit is what to write in case of1, and the next k bits (where k depends on my chosen limit) is which instruction to jump to, where a nonexistent instruction means “halt”. And so forth. Every string of bits is a valid TM, and I can encode every possible TM in this way. There’s still a problem with the last instruction possibly ending too soon, but I treat it like below.Since I don’t get to limit the maximum machine size, things get just slightly more complicated, as another symbol, say
|separates instructions, and there’s a constant time (and zero space) rule of how the interpreter responds if|is encountered before the first 4 bits have been read, e.g., they’re treated as all zeros and a “halt” (Keep in mind that I helped LC even more by allowing variable shadowing which increases evaluation cost more significantly that in my TM encoding).But the point is this: however many encoding games you allow in each formalization (which depends on how much leeway do you give in changing the complexity of each step; for example, in my above encoding, at worst I would need O(n) time and O(1) space to verify, which is still significantly less than required even for untyped LC), the difference between the strictest and most lenient would be slight (something like n^2 time or log n space at most). OTOH, the differences between machine models and typed language models are huge (exponential and much, much larger). That is not surprising: the typed models do extra work (proof checking), so someone must pay for solving two problems instead of one.
LikeLike
This clears things up a bit for me. Two follow-up questions though:
I know they can still be validated in linear time, but how are strings of
bits with fewer than 4 bits handled?
How does, for example, the untyped lambda calculus interpret the
string-of-bits computation encoding, in the sense of “the first bit means X to
the model, which will execute it in such-and-such a way”.
LikeLike
As in the description in the second paragraph, when encountering strings with fewer than 4 bits can, e.g., the machine can decide to treat all missing bits as 0.
With untyped LC things are more complicated because parentheses are meaningful (the same expression with parentheses in different positions means a different computation), so you need to count parentheses. In typed LC, there’s type checking involved. Type checking itself may be — in some typed systems — arbitrarily powerful, so there may be more computation involved when validating the expression than evaluating it.
LikeLike
Ah, so this is equivalent to picking any enumeration of a TM and implicitly mapping strings to TMs. Then every string is valid and the answer is always “yes.” This throws away the syntax and everything the PL people care about, which is the whole point.
LikeLike
Almost. It’s not like picking “any enumeration”, because the encoding must satisfy the property that it is directly interpretable by the appropriate model, with little to no additional work. You could also enumerate LC programs, but in order to apply reductions, there would need to be an expensive translation step. There’s no expensive translation step needed here (or for any of the other machine models).
LikeLike
This is the question by which we say machine models are qualitatively different to language models, saying that if the complexity of validating the computation is more than zero then the model is a language model. Is this to indicate that the latter are more complex, and unsuited for thinking about computation? But, machine models validate such bit strings with zero complexity because bit strings are valid encodings of machine model computations by construction. I feel you could make the same argument in reverse: What is the computational complexity of deciding whether a given lambda expression (or whatever primitive a given model uses) encodes a valid computation in a given model? Or is it because the bit string is a naturally occurring primitive of the physical machine that we should only consider bit strings as encodings of computations?
As a separate note, I’m interested in the meaning of Leslie’s comment:
Is the statement that TLA+ can do things that TMs can’t based on the fact that it can decide whether a TM will halt? Isn’t that a bit fallacious, unless TLA+ can decide whether another TLA+ program will halt?
LikeLike
That’s precisely why it’s a good thing that computational complexity is absolute. I’ve edited the article to elaborate (see the discussion of the “NP solving language”). Some typed LC formalisms are Turing-complete in their validation step! In other words, it’s hard to cheat. You know when you can solve a hard problem in your validation step (because you know what constitutes a hard problem).
The
+in TLA+ is ZF set theory (and the TLA is the more interesting temporal logic of actions that works on state machines), so TLA+ lets you specify non-recursive sets. Specifying something in math is very different from deciding it. So, yes, you can specify a program that given an input program decides halting, just as your able to specify that a program behaves in this way in English. But you won’t be able to realize and run your program on a computer. TLA+ lets you specify things that you can’t actually compute because it’s ordinary math. But if you specify something that’s non-computable, you won’t be able to prove that a realizable program encoded in TLA+ computes it.The difference between this “ordinary” math and type systems, is that type systems don’t even let you say some things (e.g. that are not computable). However, the very same (hard) work of proving whether what you’ve said is computable or not is done in both formalisms. It’s just that in the typed formalism, that work is done during the validation phase, while in TLA+ the validation step is rather trivial, whereas the work is done in the “proving/computing” stage.
LikeLike
In computability theory there is a criterion on what makes a “reasonable” or “correct” interpretation of a Turing machine, known as “acceptable representation” or “acceptable numbering”. You can look it up, but the idea is that machines should be represented in such a way that the s-m-n and u-t-m theorems both hold. In terms of λ-calculus this says that function application and currying must be computable. A machine representation which contans information about the machine halting will fail the s-m-n theorem.
LikeLike
In the context of the post I am more concerned with complexity than with computability, the central point being that a particular representation can do much of the computational work, as indeed typed representations do (i.e., the representation already carries an additional certificate “b“, whose computation is of non-negligible complexity), and comparing the complexity of the representation language can tell us whether we’re looking at similar or substantially different representations. Nevertheless, I take your point that as far as computability is concerned, and when the object represented is a program, the condition you cite is indeed sufficient to reject a halting-problem-eliminating representation (I assume because you cannot compute the halting value for the curried function from the uncurried one).
LikeLike
You’re begging the question here. If you assume that computation is about operating on bitstrings (or slightly generally, on sequences of symbols from some alphabet), of course you’ll conclude that models that model computation as operating on bitstrings are better models of computation than models that model computation another way. If you started from the assumption that computation was about operating on well-formed System Fω expressions, then you’d find bitstring-based representations to be bizarre and perverse, since it takes a substantial amount of computation to figure out computational properties of a given bitstring that are obvious in the System Fω representation.
Operating on bitstrings is the simplest model of operating on bitstrings. This shouldn’t be a surprise. It doesn’t prove anything about how suitable it is s a model of computation.
Amazing how two people can see the same facts but interpret them so differently. To my mind the fact that the user cares about the pictures on the screen or the movement of the aeroplane’s control surfaces is precisely the point that the user doesn’t care about the bits – it doesn’t matter to the user if the picture they see was drawn by a vector display directed by a reduceron, or if the control surfaces were moved by an analogue system of wires and pulleys. What the user cares about is in a very real sense the function implemented by the computation – that the picture on their screen is of the same scene that their friend pointed their camera at, that the control surfaces be positioned in such a way that the plane turns to the left whenever the stick is pulled to the left and to the right whenever the stick is pulled to the right.
Again begging the question. If you see sets as fundamental, these are two distinct problems. But the problems we talk about when we talk about computation tend to involve an output rather more structured than a bitstring. The computer doesn’t just need to send some pattern of signals on the wire to the monitor, it needs to send a valid picture: a computer program that sets the wires to a pattern that causes the monitor to not display anything (or worse, to burn out some of its components) is not even wrong. A flight computer that sends some arbitrary bitpattern along the wire to the control surface actuators (e.g. one corresponding to a movement that’s not physically possible) is not even wrong. So computing well-typed values is closer to what we talk about when we talk about computation than computing bitstrings or set elements.
Be that as it may, I’d hold that learning and evolution are not, at least for the overwhelming majority of people, what we talk about when we talk about computation. Your chemist-architect comparison is fair, but an architect would rightly be a bit miffed if the chemist offered it up as “what we talk about when we talk about building design”. There’s space for a discipline that investigates the complexity behaviour of physical processes, but the discipline that Gödel and Church were working in has the better claim on the name “computation”.
LikeLike
Not at all, because I make no claim about being better or worse, just provide an objective measure (language complexity) to show that they are different. As we then have two distinct classes, the only question is which of them gets the name “computation” and which the name “programming”. I think I follow the clear consensus in that regard.
You can take “bits” here to mean any physical phenomenon that doesn’t have an a priori meaning (as opposed to languages, that do). In any event, the crucial point here is that we’re talking about two different forms of collaboration with a program. The user that interacts with its physical manifestation and the programmer that’s required to perform the computational task necessary to construct well-formed terms in the programming language.
But what makes the picture valid need not be some meaning represented by a meaningful mathematical concept in the formal language used to describe the program. Proof: you see the ocean and it means something to you. Yet the ocean wasn’t programmed in a language whose terms encode the meaning of ocean to humans. This idea was at the core of Turing’s philosophical revolution (on which I expound in my book, https://pron.github.io/computation-logic-algebra). Up until Turing it was explicitly assumed that meaning cannot arise unless it’s baked into the atoms of the system that gives rise to it. Turing showed that this is false. That meaningful languages can be faithfully represented by meaningless computation.
On the contrary. The first to ever use the word computation in its modern sense was probably Leibniz in the 17th century (who wrote “When God calculates… the world is made”. inspired by Thomas Hobbes. The inspiration there was very much the inner workings of God’s creation, from simple animals to the human mind, and that is what Leibniz claimed would be possible to capture in his formal logic and “reasoning calculus”. This view continues through the nineteenth and twentieth centuries. That computation applies first and foremost to human-made software is a very recent development. In fact, even when people like Charles Sanders Peirce were working on lattice theory and Boolean algebra, they believed those theories were useful because they captured how the brain’s neurons operate (the paper that first established lattice theory begins with this exact description). Today, most theoretical computer scientists mean precisely this form of computation as a physical phenomenon when they say computation, as most computational theory applies (and is used to study) man-made as well as natural computation.
LikeLike
But there’s nothing objective about choosing “how complex is the translation between this representation and a bitstring-ey representation” as your measure; if you were to choose “how complex is the translation between this representation and a System-F-ey representation” as your measure you’d reach the opposite conclusion.
We all always agreed there were two distinct classes; Harper’s post makes the same division. All that defining the function that measures how bitstring-like a given representation tells us is that the class of bitstring-like representations are more bitstring-like.
But the non-programmer user of a program will be interacting it not as a random physical phenomenon (“what a curious arrangement of lights and colours”), but as something that carries meaning to them (“that’s a picture of my friend’s cat”).
But a picture isn’t a computation, an ocean isn’t a computation, and our terminology should reflect that. So you can’t separate the computation from the meaning; the difference between the physical occurrences that we call computation and the physical occurrences that we don’t call computation, between a computer and a non-computer, is precisely the presence or absence of that kind of meaning.
LikeLike
First, that’s not quite the measure I use. The measure is what is the complexity of the formal language. That is very much an objective measure, and it can be zero or non-zero, and it does not depend on the computational model. If you use a different data structure (say, a tree), you’ll find that that representation contains more algorithmic information than a string. You can use Shannon entropy, Kolmogorov complexity or any such measure —
you’ll get the same result. Language representations contain more information because some computational process paid its cost. Second, like Harper, it seems like you think this is some sort of competition. It isn’t. The difference in complexity is absolute, and all it shows that the two representations are different and one is “lower”. There is no value measure associated with it. Quite the contrary — this difference in an absolute intrinsic measure shows that the two different models are worthy of different names, and are not comparable.
Not quite. Harper’s post compares the two systems using some (aesthetic) value measure that he chooses. I show that that value is computational work that is bought and paid for. In general, Harper tries to convince that something is “better” than another, by defining “better” in some way. I point out that it’s a quality that you buy. Sometimes you may want to pay for it and use it, and sometimes you may choose not to use it, in which case you don’t pay for it. He basically says that a Porsche is “better” than a bicycle; I’m pointing out that such a comparison is hard to make.
I didn’t say random.
Of course, but that meaning does not emerge from meaning that was baked into the formalism used to express the program. That same program expressed in any formalism whatsoever would carry the same meaning to the user, despite having very different formal semantics (at least very different denotational semantics). That was precisely what Turing discovered. In order for meaning to emerge from computation, it does not have to exist in the language used to create it.
Most theoretical computer scientists would disagree. TOP is concerned with human programmers; TOC is concerned with any kind of computation, as the statement by the leading theoreticians I quoted explicitly states.
An ocean carries a lot of meaning to me, and, I think to most people and animals.
LikeLike
There’s nothing objective about choosing to measure the complexity of deciding whether a given string representation corresponds to a valid program. Of course if we measure complexity in terms of string encodings then we find a tree contains more information than a string, but that’s begging the question.
I think you’re being a little too mystical and imaginative here. A meaningless process can faithfully represent/model a meaningful computation, and this is a surprising and important insight from Turing. But the kind of computation we want to talk about doesn’t arise spontaneously in nature; rather we start from caring about a particular meaning, and then find a physical model of that meaning. And, formally or not, we’ll think about that meaning and use that meaning to construct the implementation, and if formal semantics are to be useful then they should reflect that meaning.
If we want to study, say, the computation being performed by a mechanical calculator, we would start from the meaning: understanding it as a device that performs arithmetic and then drilling down into particular gears representing addition or multiplication or intermediate results or… Of course the gears and axles are pieces of metal that don’t inherently have any meaning, but most pieces of metal don’t compute in any meaningful sense, so while we could study the forces and motions of the physical gears, at that point we wouldn’t be studying computation any more. (Likewise, we could probably study the calculator in terms of a formalism that had no concepts of numbers or arithmetic, but again we wouldn’t be studying the computation any more).
Well, we already have a term for the study of any kind of physical phenomenon – “physics”. If you consider the study of ocean behaviour to be the study of computation, is there any kind of physics that isn’t the study of computation? If not, why define another word to mean the same thing?
The meaning – the computation – rests not in the ocean but in our minds. We may regard the ocean as wet, or vast, or unexplored, or tranquil, but you won’t find that semantic structure in the ocean itself.
LikeLike
The string representation is not the point. This works for any representation, provided that you take into account the algorithmic information in the representation. I don’t know if “objective” is the best word here (after all, eye color is an objective metric, but it may not be a very interesting metric for classifying people); the important point is that it’s absolute. Any piece of data contains an absolute amount of algorithmic information. A lambda expression — in any representation — contains more information than a TM or a cellular automata system implementing the same computation. That algorithmic information must be paid for in algorithmic work is a theorem. A string is just convenient as producing an arbitrary (not random) string has an algorithmic complexity of zero or very close to it, while an arbitrary tree has a higher algorithmic cost.
Who wants to talk about? Certainly not TOC theorists. TOP theorists want to talk about man-made programs, and what they’re talking about is programming, not computation. Defining which is which is, as I’ve shown, a matter of an absolute mathematical quality.
I agree. But that’s called programming, and is not found in all computation.
I disagree. The metal in my heater computes its temperature, which is very meaningful to me. But I gave a much better example. DNA and brains certainly compute in a more traditional sense — they even display modularity and other desired features — yet they are not programmed using compositional semantics. So even clearly “high” computation does not require a language with the aesthetically appealing property (to humans) of syntactic compositionality.
No. First of all, theoretical computer scientists really do study natural computation all the time. If you have an issue with what most CS theorists call what they study — take it up with them. Second, while CS theorists very often study things that overlap with physics (you can see that by reading, say, Scott Aaronson’s blog; sadly, TOC researchers have a much smaller online presence than TOP theorists, even though they are greater in numbers) there are some (blurry) separation lines. Physicists are mostly interested in continuous processes or simple discrete ones, while computer scientists are more interested in complex discrete systems. Also, why physics? Physicists aren’t the only scientists studying nature. Indeed, there is overlap between computer science and biology as well (it was Alan Turing who created the field of computational biology). The starting point of natural science and theoretical computer science is often different, though. Natural science usually begins by studying a concrete and specific natural system; computer science starts with abstract computational processes, that may be realized in natural or artificial systems.
But that’s the whole point! Meaning is always in our minds, but until Turing it was thought that if meaning is to arise from computation, the language used to describe the computation must be compositionally mapped to the concepts of the human mind. Turing showed that it can be applied post hoc. My book covers this fascinating development in great detail: https://pron.github.io/computation-logic-algebra Computation is an intrinsically meaningless process to which people may ascribe meaning. Programming is creating computation by using a contentual language. What I showed in this post is that the use of a contentual language is not an arbitrary choice, but requires computational work by the programmer. The meaning baked into the programming language is additional information — not required for the computation but helpful for the programmer — that some other computational system (the programmer) must work to produce.
LikeLike
But you can’t define “information in the representation” non-circularly! The only way you can define how much information there is in a given representation is how much computation it takes to transform it to/from another representation, and which representation you choose to measure from is an arbitrary choice.
My experience is that CS theorists, Aaronson included, study processes that have meanings, even if they don’t necessarily realise that’s what they’re doing. Aaronson talks about “bits and integers” as being somehow more primitive than types, but this is backwards: you can’t even define those concepts (in a way that corresponds to the way we actually use them) without types.
(When everything you’re doing is first-order, simply inductive, it’s possible to imagine that bits and integers are primitive, and abuse notation or handwave away the occasional edge cases, so those working with simple computations and simple computers can get away with seeing it that way for the most part, but this worldview is incoherent and collapses if you push it too hard)
It’s not just arbitrary processes though; if you look at it from a process perspective, certain kinds of processes attract a lot more interest than others (and what even is a “process” in this sense?). I contend that it’s more accurate to say computer science starts with functions (not in the set-of-ordered pairs sense but in the constructive type-theory sense), that may be realised in natural or artificial systems.
But if you decide that the ocean must be computing because it means something to you, you’re making the equal and opposite error. A mechanical calculator evaluating an expression or a Turing machine running a tape are clearly doing something different (or, at an absolute minimum, something that we find it useful to study in a different way) from what the ocean does. We need to be able to draw a line between computation and non-computation if “computation” is to mean anything, and for “computation” to be a good name for that line, our technical definition needs to line up with people’s intuitions at least in the “easy” cases. Almost everyone, theorist or not, would say that neither an ocean nor a radiator computes; if you’re defining “computation” in such a way that they do then your definition is a poor one.
LikeLike